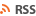검색결과 리스트
분류 전체보기에 해당되는 글 101건
- 2021.03.21 [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하고 Deposit하기(4) 4
- 2021.03.21 [암호화폐-Defi] 안정적으로 연20-25% 수익이 나는 DeFi
- 2021.03.21 [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하기(3)
- 2021.03.03 [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2) 4
- 2021.03.03 [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(1)
- 2021.02.10 [암호화폐-Defi] Mirror 2
- 2021.01.17 [시스템트레이딩] 전략 시뮬레이션(9) - 과거 데이터(체결, tick데이타) 연속으로 가져오기
- 2021.01.12 [시스템트레이딩] 전략 시뮬레이션(8) - 과거 데이터(분봉) 연속으로 가져오기 18
- 2020.12.27 [파이썬] 시간 다루기 1
- 2020.12.23 [파이썬] glob, os 정리, 폴더(dir) 그리고 파일 다루기 1
글
[암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하고 Deposit하기(4)
그동안 소개한 파이썬을 이용한 BSC Smart Contract 관련 글을 모두 모아서 pancakeswap에서 채굴 중인 pool 중 특정 수량 이상 harvest된 pool에 있는 cake을 harvest한 후 정해놓은 syrup 풀에 deposit하는 파이썬 프로그램을 완성하였습니다. 이제는 파이썬 프로그램에 규칙을 등록해놓으면 알아서 harvest하고 deposit할 수 있습니다.
소스는 아래 guthub에 있습니다.
github.com/multizone-quant/DeFi/blob/main/DeFi_harvest_deposit
사용법은 간단합니다.
아래 부분에 원하는 값을 입력하시면 됩니다. my_addr는 본인이 사용하는 eth주소, my_priv는 해당 주소의 private key입니다. claim, deposit을 하기 위해서는 private key가 필요합니다.
POOL_NAME는 수정할 필요가 없고, MIN_HARVEST_NUM 값은 claim할 최소 갯수입니다. 이렇게 claim한 cake은 DEPOSIT_POOL에 지정된 pool에 deposit합니다.
현재 test한 syrup풀은 alice이며 본인이 사용하는 syrup pool의 smart contract를 찾아서 추가하면 됩니다.
# 수정할 부분
my_addr = 'my eth address'
my_priv = "my_addr's priavate key"
POOL_NAME = 'pancake-masterchef'
MIN_HARVEST_NUM = 2.3 # harvest할 최소 수량
DEPOSIT_POOL = 'syrup-alice' # harvest한 cake을 저장할 pool
# 수정할 부분 끝새로운 syrup 풀을 추가하는 방법은 bscscan.com에서 pool의 주소를 확인한 후 sc_addr에 추가하면 됩니다.
sc_addr = {
'bnb-busd' : '0x1B96B92314C44b159149f7E0303511fB2Fc4774f',
'cake-bnb' : '0xA527a61703D82139F8a06Bc30097cC9CAA2df5A6',
'ust-nflx' : '0xF609ade3846981825776068a8eD7746470029D1f',
'syrup-alice' : '0x4C32048628D0d32d4D6c52662FB4A92747782B56',
}
contract 별로 abi가 별도로 존재하는데, 이것을 자동으로 가져오는 함수도 발견하였습니다. 관련 함수는 fetch_abi() 입니다. 한번 사용한 contract는 컴퓨터 내부에 저장하고 있으므로, 이후에는 빠른 처리가 가능합니다.
pancakeswap masterchef에 있는 pool 중 BRY-BNB에 있는 BRY smart contract가 조금 이상합니다. name() 항목이 abi가 존재하지 않아 오류가 발생하더군요. 그래서 cake-bnb abi를 이용하여 모든 pool에 대하여 사용하는 방식으로 오류를 회피하였습니다.
코드는 간단하므로, 자세한 설명을 생략합니다.
실행한 결과입니다. 2.3개이상 채굴한 두 pool이 claim되었습니다.

그 결과를 bscscan에서 확인해보겠습니다. 풀 2개에서 cake이 claim되었고, alice pool에 deposit되었습니다. 그동안 alice pool에서 채굴 중이던 alice도 claim되었군요. 이건 자동으로 이루어지는 것입니다.

다음 편에서는 cake 가격이 특정 가격 이상이면 시럽에 deposit하지않고 busd로 swap하는 코드까지 소개하도록 하겠습니다.
'암호화폐' 카테고리의 다른 글
| [암호화폐] 무위험 차익거래, 암호화폐매수/선물매도 (1) | 2021.04.13 |
|---|---|
| [암호화폐-Defi] 안정적으로 연40% 수익이 나는 DeFi (0) | 2021.04.06 |
| [암호화폐-Defi] 안정적으로 연20-25% 수익이 나는 DeFi (0) | 2021.03.21 |
| [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하기(3) (0) | 2021.03.21 |
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2) (4) | 2021.03.03 |
글
[암호화폐-Defi] 안정적으로 연20-25% 수익이 나는 DeFi
요즘 이자 수익률이 1%대 입니다. 상당히 낮은 수익률이죠.
하지만 DeFi 쪽으로 눈을 돌리면 아주 아주 안정적으로 20% 이상의 고수익을 얻을 수 있습니다. 그것도 방법이 아주 많습니다.
이번에는 리스크 (거의) zero인 stable coin을 이용한 defi 수익률을 정리해보고자 합니다.
우선 stable 코인에 대한 정의가 필요한데요.
stable 코인은 US$1을 추종하는 코인입니다. 여기서 추종한다는 의미는 노력한다는 의미이지 반드시 1불을 따라간다는 것은 아닙니다. 일시적으로 1불을 지키지 못하는 경우도 있지만 대부분 $1을 지킵니다.
그럼 stable 코인으로 staking을 하면 staking 토큰의 가치가 하락할 일은 없으니, staking한 자산의 가격 변동성에 대하서는 무시하면 됩니다. 남은 것은 제공하는 이율만 신경을 쓰면 됩니다.
1. pancakeswap
https://exchange.pancakeswap.finance/#/swap
BSC 체인의 대표적인 defi 사이트죠.
현재 20-30% 정도 수익률이 나옵니다.

2. venus
https://app.venus.io/dashboard
BSC 체인에서 대표적인 lending 사이트입니다. usdt, busd 수익률이 약 16%, 추가로 이것을 담보로 VAI mint한 후 staking하면 8% 정도 나옵니다. 합하면 24%

3. uniswap
분산거래소가 가장 유명한 곳이죠. 여기에 LP 공급을 하면 수수료인 0.3%를 LP 공급자에게 지급합니다. 수익은 거래량에 비례하는데 안정적인 usdc/usdt pair의 경우에 연 10-20% 사이 나옵니다.

4. 가끔씩 나오는 핫한 사이트입니다.
오늘 출시된 따끈뜨끈한 사이트입니다.
말이 안되는 수익률이지만 현재는 이렇습니다. 앞으로는 계속 떨어질 것으로 예상합니다.
이런 사이트는 믿음이 중요한데, 믿을만한 곳이 아니면 투자를 하면 안됩니다.

결론적으로 자동매매로 이정도 수익률이 나온다는 보장이 없어서 요즘은 DeFi 위주로 투자하고 있습니다.
--------------
defi를 이용하기 위해서는 binance 거래소 계정이 필요합니다. 아래 링크로 가입하시면 수수료 10% DC 됩니다.
'암호화폐' 카테고리의 다른 글
| [암호화폐-Defi] 안정적으로 연40% 수익이 나는 DeFi (0) | 2021.04.06 |
|---|---|
| [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하고 Deposit하기(4) (4) | 2021.03.21 |
| [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하기(3) (0) | 2021.03.21 |
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2) (4) | 2021.03.03 |
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(1) (0) | 2021.03.03 |
글
[암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하기(3)
node.js를 이용한 방법은 많이 나와있지만 파이썬을 이용한 방법을 찾지 못하여 어렵게 방법을 찾았습니다.
어디에도 없는 파이썬을 이용한 BSC Smart Contract에서 claim하는 방법에 대하여 정리합니다.
pancakeswap 중 syrup에 있는 Alice pool에서 채굴 중인 cake을 자동으로 claim하는 코드입니다. 다른 pool의 경우에도 주소만 변경하면 같은 방식으로 claim이 가능합니다.
우선 alice 채굴 풀의 주소입니다.
'syrup-alice' : '0x4C32048628D0d32d4D6c52662FB4A92747782B56'
이 주소에 접속한 후 contract 부분을 보면 아래와 같은 정보를 확인할 수 있습니다.
- 현재까지 채굴된 cake 수 : pendingReward(my_addr)
- 현재까지 채굴된 cake claim : withdraw(0)
alice 채굴풀의 Smart Contract에서 채굴한 수량을 검색한 후 일정 수량이상 쌓여있다면 withdraw()를 하면 됩니다.
pendingReward() 함수는 직관적이라 설명을 생략하고요. 채굴된 cake을 claim하는 함수가 withdraw()입니다. 그런데 deposit한 cake도 뺄 때 사용하는 함수입니다. 따라서 deposit한 cake은 빼지않고, reward만 claim하는 방법은 인자로 0을 넣으면 됩니다.
pancakeswap에서 claim을 해보면 지갑이 뜨고, Confirm을 눌러야 claim이 됩니다. 이런 일을 코드로 전달해주어야 합니다. 그런데 이 부분이 아주 난감했습니다만, 어찌어찌하여 방법을 알아내었습니다.
코드는 아래와 같습니다.
sc_addr = {
'bnb-busd' : '0x1B96B92314C44b159149f7E0303511fB2Fc4774f',
'cake-bnb' : '0xA527a61703D82139F8a06Bc30097cC9CAA2df5A6',
'ust-nflx' : '0xF609ade3846981825776068a8eD7746470029D1f',
'syrup-alice' : '0x4C32048628D0d32d4D6c52662FB4A92747782B56',
}
sc_abis = {
'syrup' : '[]' # abi 코드가 길어서 삭제함.
}
my_addr = 'my eth address'
my_priv = 'my private key'
w3 = Web3(Web3.HTTPProvider('https://bsc-dataseed.binance.org/'))
print(w3.isConnected())
# alice harvest
if 1 :
addr = sc_addr['syrup-alice']
abi = sc_abis['syrup']
syrup = w3.eth.contract(address=addr, abi=abi)
pending = syrup.functions.pendingReward(my_addr).call()
print(pending)
tx = syrup.functions.withdraw(0).buildTransaction({ # 채굴한 코인 claim시에는 0
'gas': 150000,
'gasPrice': w3.toWei('10', 'gwei'),
'nonce': w3.eth.getTransactionCount(my_addr),
})
signed_tx = w3.eth.account.signTransaction(tx, private_key=my_priv)
ret = w3.eth.sendRawTransaction(signed_tx.rawTransaction)이 코드의 결과를 bscscan에서 확인해보겠습니다.

원하는 결과가 나왔습니다.
앞으로는 주기적으로 자동으로 claim하고, 원하는 곳에 deposit을 할 수 있을 것 같습니다.
그동안 소개한 Smart Contract를 다루는 방법을 모아서 pancakeswap에서 채굴 중인 cake을 claim한 후 syrup pool에 deposit하는 작업을 마무리한 후 코드 공개하도록 하겠습니다.
'암호화폐' 카테고리의 다른 글
| [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하고 Deposit하기(4) (4) | 2021.03.21 |
|---|---|
| [암호화폐-Defi] 안정적으로 연20-25% 수익이 나는 DeFi (0) | 2021.03.21 |
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2) (4) | 2021.03.03 |
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(1) (0) | 2021.03.03 |
| [암호화폐-Defi] Mirror (2) | 2021.02.10 |
글
[암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2)
BSC DeFi에 대한 간단한 소개에 이어 이제 실전으로 들어가보겠습니다.
우선 web3.py를 설치하여야 합니다. 설치 방법은 아래와 같이.
pip install web3
DeFi 프로젝트에 따라서 smart contract을 만드는 방식이 다양합니다. 따라서 사이트에 맞게 필요한 smart contract 주소를 잘 찾아야합니다. 예제로 선보인 pancakeswap은 아래와 같은 구조로 구성되어 있습니다.
pancakeswap 풀에 있는 모든 풀은 MasterChef라는 이름의 smart contract 만들어져있습니다. 각각의 풀도 smart contract이고 각 풀에 있는 token들도 smart contract로 만들어져있습니다.
각각의 smart contract 주소는 아래와 같습니다.
MasterChef : 0x73feaa1eE314F8c655E354234017bE2193C9E24E
|
+-- Cake-BNB LP : 0xA527a61703D82139F8a06Bc30097cC9CAA2df5A6
|
+ Cake : 0x0E09FaBB73Bd3Ade0a17ECC321fD13a19e81cE82
+ Bnb : 0xbb4CdB9CBd36B01bD1cBaEBF2De08d9173bc095c
전 글에서 언급하였듯이 smart contract의 ABI가 필요합니다. bscscan에 접속하여 해당 주소를 입력한 후 ABI 값을 복사해옵니다.
Cake-BNB LP와 Cake, Bnb의 경우에는 Cake-BNB LP smart contract를 사용합니다. 일반적인 smart contract에 있는 함수만 사용하기 때문에 각각의 ABI 파일을 다운받을 필요가 없지만 각 contract 고유의 기능을 사용하려면 별도로 모두 받아야합니다. 이 절차가 조금 번거롭기는 합니다.
파이썬 프로그램으로 해당 smart contract의 값을 읽어오는 절차입니다.
우선 bsc network으로 Web3를 기동시킵니다. 사용하는 블럭체인에 맞는 주소를 입력해주면 됩니다.
w3 = Web3(Web3.HTTPProvider('https://bsc-dataseed.binance.org/'))
다음으로는 검색할 pool에 대한 주소와 ABI 값을 dict구조에 추가합니다. 앞으로 여러 pool을 대상으로 검색을 할 수 있도록 dict 형태로 작업을 했습니다.
그리고 common abi도 하나 복사해두었습니다. 이건 Cake-BNB LP에서 가져온 ABI입니다.
이러한 정보를 바탕으로 w3.eth.contract() 함수를 호출합니다.
pools = {
'pancake' :
{ 'addr':'0x73feaa1eE314F8c655E354234017bE2193C9E24E',
'abi' : '[{"inputs":[{"internalType"...]' # 너무 길어서 생략
},
}
# 일반적인 풀의 abi. 만약 함수명이 틀린 풀이 있으면 해당 풀의 abi로 대체
contract_common_abi = '[{"inputs":[],"payable":false, ...]' # 너무 길어서 생략
def pool_info():
for name in pools :
ee = w3.eth.contract(pools[name]['addr'], abi=pools[name]['abi'])
pancakswap MasterChef ABI를 보고서 필요한 함수를 부릅니다. 이 ABI에는 pool의 갯수를 알려주는 함수가 있습니다. 풀 갯수만큼 루프를 돌리면서 본인이 staking한 풀에 채굴된 cake 수량을 출력해주는 함수입니다.
# 풀의 총 갯수를 얻는다.
poolLength = ee.functions.poolLength().call()
for 풀 수량 만큼 :
# 해당 풀에 deposit한 수량을 얻는다.
user_info = ee.functions.userInfo(i, my_addr).call()
# 만약 내가 staking한 pool이면
if user_info[0] > 0 : # for only staked pools
# 풀에 대한 정보를 얻는다.
poolInfo = ee.functions.poolInfo(i).call()
# deposit한 LP 수량을 얻는다.
deposit = user_info[0] / (10 ** 18 )
# 채굴된 cake의 수량을 얻는다.
pending_cakes = ee.functions.pendingCake(i, my_addr).call()
pending_cakes_real = pending_cakes/(10 ** 18 )
# 해당 풀의 smart contract 주소를 얻는다.
addr1 = poolInfo[0]
# 해당 풀의 토큰의 주소와 abi로 smart contract 정보를 얻는다.
e1 = w3.eth.contract(addr1, abi=contract_common_abi)
# 1번 토큰의 주소를 얻은 후 smart contract 정보를 얻는다.
token1 = e1.functions.token0().call()
t1 = w3.eth.contract(token1, abi=contract_common_abi)
# 1번 토큰 정보를 얻는다
name1 = t1.functions.name().call()
sym1 = t1.functions.symbol().call()
# 2번 토큰의 주소를 얻은 후 smart contract 정보를 얻는다.
token2 = e1.functions.token1().call()
t2 = w3.eth.contract(token2, abi=contract_common_abi)
# 2번 토큰 정보를 얻는다
name2 = t2.functions.name().call()
sym2 = t2.functions.symbol().call()
print("[%6s - %6s] %10.3f %10.3f"%(sym1, sym2, deposit, pending_cakes_real))
결과를 확인해보겠습니다.

화면에서 보는 수량과 일치하는 값을 얻을 수 있었습니다.
이 방식을 기반으로 여러 DeFi 프로젝트의 smart contract 주소와 ABI 파일을 구하면 본인이 투자한 DeFi에서 채굴한 토큰의 수량을 바로 파악을 할 수 있을 것 같습니다.
다음으로 할 일은 채굴된 토큰들을 자동으로 claim하는 부분입니다. 이 또한 예제가 부실하여 아직 작업이 마무리되지 못하였습니다. 이번 주말에 작업해서 성공한다면 정리해서 올리도록 하겠습니다.
파이썬으로 BSC Smart contract를 다루는 예제를 발견하기 어려운데요. 이렇게 간단하게 구현할 수 있는 것을 아주 아주 힘들게 돌아온 것 같습니다.
본 글에 나오는 예제는 아래 github에 있습니다.
'암호화폐' 카테고리의 다른 글
| [암호화폐-Defi] 안정적으로 연20-25% 수익이 나는 DeFi (0) | 2021.03.21 |
|---|---|
| [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하기(3) (0) | 2021.03.21 |
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(1) (0) | 2021.03.03 |
| [암호화폐-Defi] Mirror (2) | 2021.02.10 |
| [암호화폐] Hoo.com 거래소에서 hoo 코인 캐기 (2) | 2020.10.01 |
글
[암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(1)
요즘은 트레이딩 보다는 DeFi에 집중을 하다보니, 자동매매 관련 글을 못올리고 있습니다. pancake, mir 등등 안정적이면서 높은 수익률을 보여주는 DeFi가 많이 있습니다. 이외도 현재 채굴 중인 DeFi가 많다보니, 매일같이 접속해서 채굴된 코인 claim하고 현재가에 매도하는 것만 해도 많은 시간이 소요됩니다.
이렇다보니, 검증된 DeFi의 현재 staking 상황, 채굴된 토큰 수량, 심지어 현재가 기준으로 자산 평가액까지 보여주는 사이트도 등장하였습니다. 대표적인 사이트가 yieldwatch.net/ 입니다. 원하는 DeFi를 선택한 후 주소를 입력하면 현재 투자한 DeFi에 대한 시가 평가액을 보여줍니다. 한눈에 투자 상황을 볼 수 있어서 엄청나게 편리합니다.

심지어는 투자중인 DeFi를 등록하면 채굴된 토큰을 주기적으로 claim한 후 해당 LP에 추가해주는 사이트까지 등장하였습니다. 대표적인 사이트가 https://autofarm.network/ 입니다. 이 사이는 auto라고 하는 자체 token도 발행하여 타 사이트에 비하여 높은 수익률을 제공해주고 있습니다.

yieldwatch 덕분에 투자 상황을 한눈에 파악할 수 있고, autofarm 덕분에 claim하는 수고를 들기는 했지만 그래도 직접 claim하는 경우도 많이있습니다.
이에 현재 채굴 중인 Binance Smart Contract 이하 BSC 기반 DeFi의 채굴 상황을 확인하고, 필요하다면 claim까지 하는 프로그램을 만들어보고자 합니다.
BSC는 이더리움 기반이다보니 DeFi에 사용하는 smart contact는 solidity언어로 개발되어 있습니다. 이미 만들어진 smart contract를 읽고/쓰기 위해서는 다양한 언어를 이용할 수 있습니다.
전 파이썬을 주로 사용하기 때문에 파이썬을 이용하여 smart contract를 다루어 보도록 하겠습니다. 그런데 문제는 파이썬을 이용하여 BSC smart contract를 다루는 예제가 많지 않았습니다. 구글링을 통해서 조각을 맞쳐가면서 작업을 진행하고 있습니다.
우선 파이썬을 이용하여 이더리움 기반 smart contract를 다룰 수 있는 패키지는 web3.py입니다.
web3.py 덕분에 새로운 언어를 배우지 않고도 원하는 작업을 할 수 있어서 다행입니다.
다음으로는 Smart contract에 대하여 간단하게 알아보겠습니다.
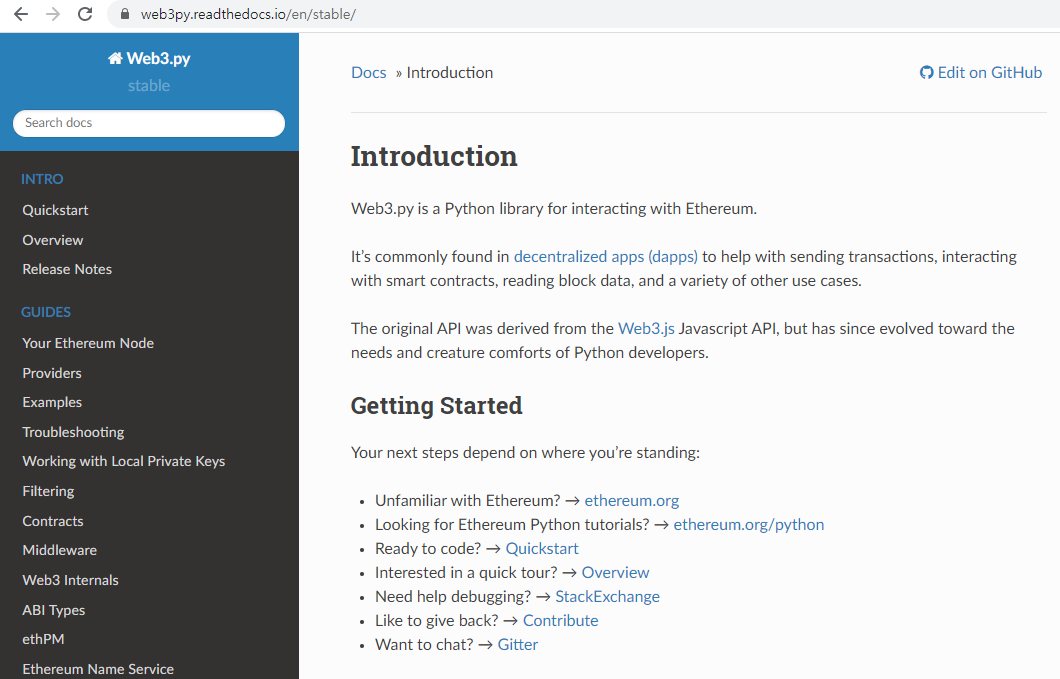
BSC DeFi 대명사인 pancakeswap입니다. 무려 80여개의 채굴 풀이 동작 중입니다. 그러다보니 본인이 채굴 중인 풀을 찾기가 힘들었었는데요. 최근 staked only 항목이 생겨서 채굴 중인 풀을 한 눈에 볼 수 있어서 많이 편해졌습니다.
채굴 풀은 smart contract로 만들어져있습니다. 한번 만들어진 smart contract는 절대 변경할 수가 없습니다. 따라서 코드 오류만 없다면 안전하다고 볼 수 있습니다. 특정 풀의 smart contract는 bscscan.com/에서 확인이 가능합니다.
pancakeswap의 smart contract 주소는 0x73feaa1eE314F8c655E354234017bE2193C9E24E 입니다.
bscscan.com에서 해당 주소를 입력해보면 아래와 같은 내용을 볼 수 있습니다. 이 중 contract를 클릭하면 해당 smart contract의 소스코드를 볼 수 있습니다.
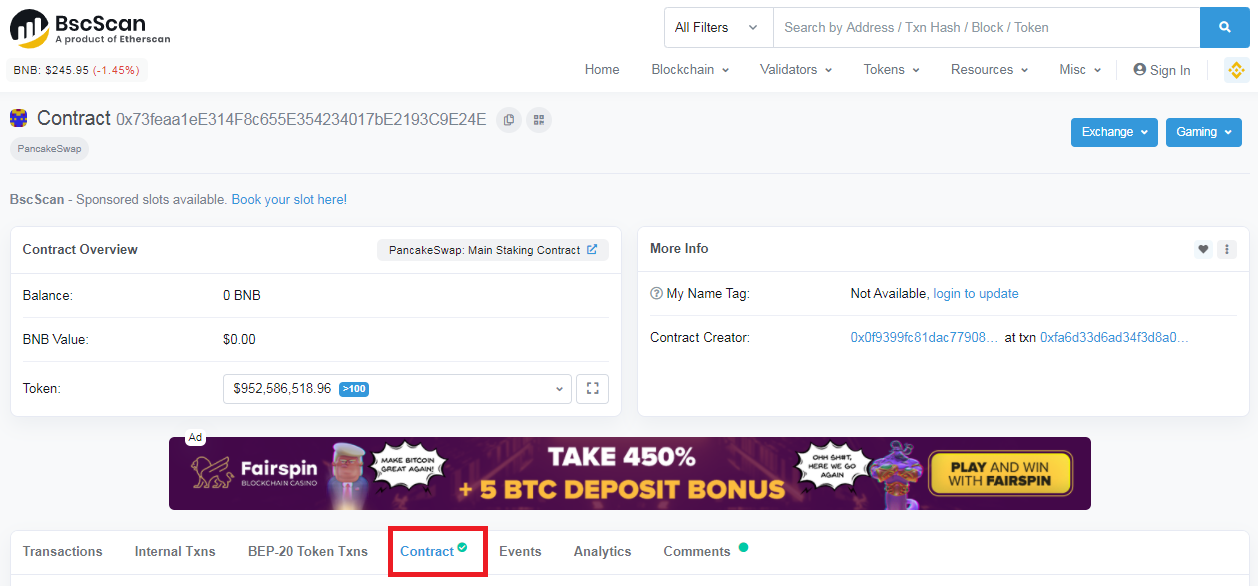
이 중 우리가 필요한 것은 ABI 입니다. abi는 Application Binary Interface의 약자로 해당 smart contract를 외부에서 사용할 수 있는 api라고 보시면 됩니다. 오른쪽에 있는 복사 아이콘을 사용하여 복사한 후 프로그램에서 사용하면 됩니다.
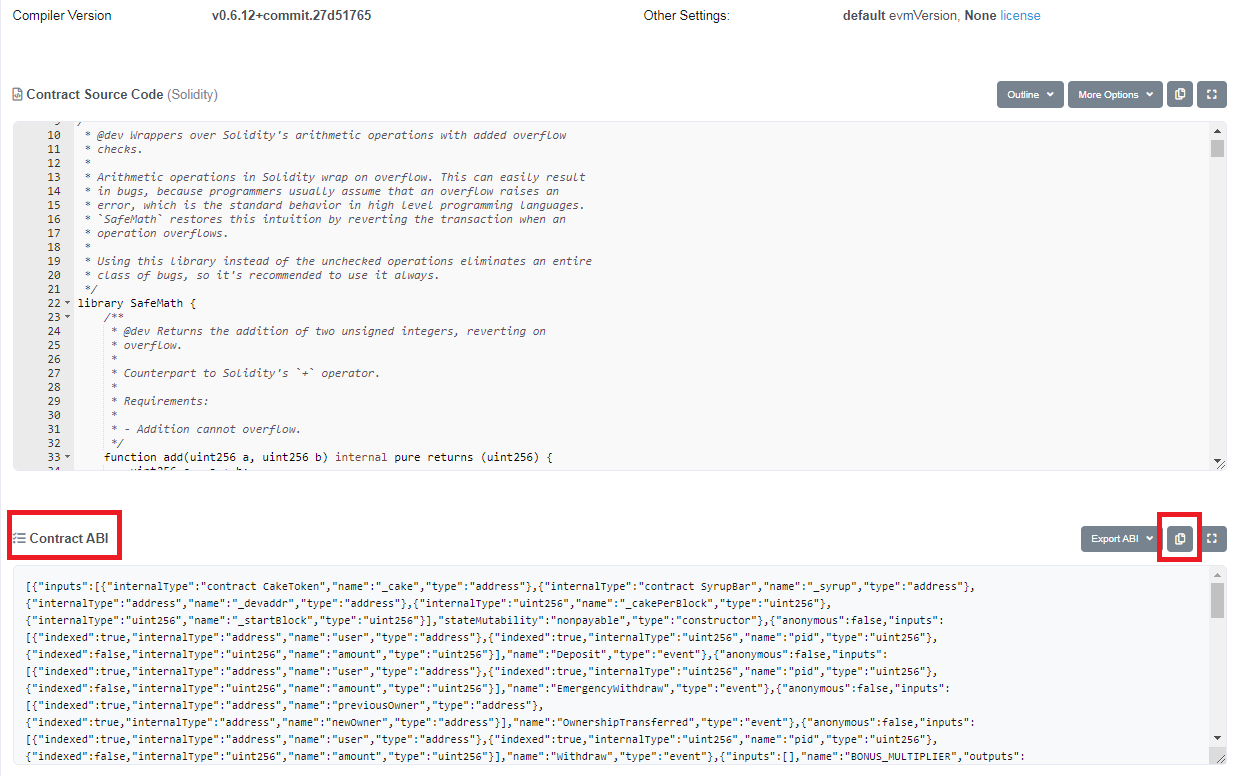
이제 pancakeswap에 있는 풀의 내용을 읽을 수 있는 준비가 되었습니다.
다음 글에서는 web3.py를 이용하여 pancakeswap 풀을 읽는 예제를 파이썬 코드로 소개하도록 하겠습니다.
'암호화폐' 카테고리의 다른 글
| [암호화폐-Defi] 파이썬을 이용하여 BSC(Binance Smart Contract) Smart Contract Claim하기(3) (0) | 2021.03.21 |
|---|---|
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2) (4) | 2021.03.03 |
| [암호화폐-Defi] Mirror (2) | 2021.02.10 |
| [암호화폐] Hoo.com 거래소에서 hoo 코인 캐기 (2) | 2020.10.01 |
| [암호화폐] Cola lending 체험기 (0) | 2020.09.29 |
글
[암호화폐-Defi] Mirror
etrade api를 이용한 시스템 트레이딩과 관련된 글을 적으려고 했는데, 내용을 정리하는데 시간이 많이 걸리는군요. 좀 더 정리해서 공개하도록 하겠습니다.
사실 요즘은 트레이딩보다는 DeFi 쪽 수익이 더 좋아서 시스템 트레이딩은 등한시하고 있는 것도 사실입니다.
제가 지난 주 부터 셋팅한 Mirror 사이트를 소개해드립니다.
Mirror는 Terra 블록체인을 사용하는 프로젝트로 Terra 재단에서 직접 개발에 참여한 프로젝트입니다. 그만큼 신뢰해도 된다는 의미입니다. 최근 BSC 기반 DeFi 몇 건에서 스캠이 발생하면서 수익률 좋은 DeFi에 무조건 참여하는 것은 조심해야 합니다. 그래서 저도 어느 정도 검정이 된 DeFi만 참여하고 있습니다.
Mirror 사이트는 아래와 같습니다.
다른 DeFi는 높은 수익률이 나오는 이유를 전혀 이해를 못하겠지만, Mirror는 대충 이해가 갑니다. Mirror는 특이하게도 미국 유명 주식과 UST pair로 LP를 만들 수 있습니다. 따라서 LP 자산에 대한 움직임에 대한 예측이 어느정도 가능합니다. 물론 알리바바가 미국 나스닥에서 상장폐지되는 사태가 생긴다면.. LP 가격도 엄청나게 빠지겠지요. 그래서 저는 비교적 안정적인 Google, Apple에 투자하고 있습니다. 추가로 VIXY는 수익률이 높아서 소액 투자하고 있고요.

Mirror에 LP 공급을 하면 수익률이 상당히 높은데요. 그 이유는 채굴 토큰인 mir의 가격이 폭등하였기 때문입니다. 불가 몇 주 전에 mir는 $1 정도였습니다. 그런데 최근에 luna 가격이 오르면서 mir도 함께 올랐습니다. 현재 가격은 $5 정도. 기존에 비하여 수익률이 5배나 올랐습니다. 그러다보니, 높은 수익률을 추구하는 사용자들이 대거 입성했습니다. 이렇게 mAsset에 대한 수요가 증가하다보니, 현재 mAsset의 가격이 약 7% 정도 프리미엄이 형성되어 있습니다.
좀더 투자를 하고 싶은데 현재는 프리가 너무 높아서 일단은 관망 중입니다. 매일 채굴되는 mir는 절반을 팔아서 ust를 만든 후 나머지 수량으로 mir-ust lp 만들어서 지속 공급 중입니다.
연 300% 정도를 일복리로 재투자하면 1년 후에 약 10배가 넘습니다. 물론 mir 가격이 $5을 유지한다는 가정입니다.
트레이딩으로 일 0.7%를 지속적으로 얻기가 쉽지 않습니다. 하지만 mir에서는 이게 가능합니다.
아직도 mir 가격이 높게 유지되는 과정이 정확하게 이해는 안되지만, 시장에서 수요가 많기 때문이라고 생각됩니다. 이 수요는 mir-ust lp로 얻을 수 있는 수익이 연 209% 라는 사실때문이겠죠.
앞으로 mir 가격의 방향에 따라서 mir defi의 방향이 정해질 것 같습니다. 아직은 순항 중입니다.
'암호화폐' 카테고리의 다른 글
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(2) (4) | 2021.03.03 |
|---|---|
| [암호화폐-Defi] BSC(Binance Smart Contract) 검색하기(1) (0) | 2021.03.03 |
| [암호화폐] Hoo.com 거래소에서 hoo 코인 캐기 (2) | 2020.10.01 |
| [암호화폐] Cola lending 체험기 (0) | 2020.09.29 |
| [암호화폐] gate.io 거래소 api (0) | 2020.09.23 |
글
[시스템트레이딩] 전략 시뮬레이션(9) - 과거 데이터(체결, tick데이타) 연속으로 가져오기
BTC 불장으로 암호화폐 시장이 활황입니다. 이 흐름이 알트 코인으로 넘어오지는 않았지만 100% 넘게 오르는 코인도 자주나옵니다.

이런 종목이 오르기 시작하는 시점에 잡아서 쭉~~ 들고 있으면 수익이 많이 나겠죠.
암호화폐 종목은 특이하게도 아침 9시 이후에 급등하는 경우가 많습니다.

그렇다면 아침 9시 근처에 체결정보를 보다가 급등하는 종목이 나오면 냉큼 매수하면 대박이 나는 종목을 모두 매수할 수 있을 것입니다. 물론 오르다 마는 종목도 있을테니 손절 종목도 나오겠지만 기프트 같이 100% 오르는 종목에서 손해를 만회할 수 있겠죠.
이런 전략을 개발하기 위해서는 과거 tick 정보를 가져와서 시뮬레이션을 해봐야 합니다.
이번에는 과거 tick 정보를 연속으로 가져오는 방법을 기술합니다.
업빗에서 tick 정보를 가져오는 url은 아래와 같은 형식을 가지고 있습니다.
api.upbit.com/v1/trades/ticks?market=KRW-BTC&count=500&daysAgo=0&to=10:00:00
받은 데이터의 형태는 아래와 같습니다.

기존 과거 candle 정보와는 형식이 틀립니다. 각 인자는 아래와 같은 의미를 가지고 있습니다.
- dayAgo : 오늘 기준으로 며칠 전 (0: 오늘 1 : 어제 최대 7일 전 )
- to : 몇시 까지 가져올지 결정 (형식 : HH:mm:ss)
- count : 최대 tick 수 (최대 : 500)
tick 자료를 연속으로 가져올 때 주의할 사항은 한번에 받는 데이터의 크기가 500개로 제한되므로, 제일 마지막 sec 자료는 모두 받지 못하는 경우가 있습니다. 따라서 연속으로 tick 정보를 받아서 합치는 경우에는 이 점을 고려해서 코딩을 해야 합니다.
또한 tick 데이터는 utc 기준으로 일자를 계산합니다. 따라서 dayAgo 값이 0이면 오늘 tick 값을 받을 수 있는데, utc 기준임을 꼭 염두에 두시고 처리하시기 바랍니다.
프로그램을 실행시킬 때 아래 인자를 수정하면 됩니다.
utc 기준으로 오늘 08시 부터 09시 BTC tick 데이터를 얻는 방법입니다.
COIN = 'KRW-BTC' # 원하는 코인 정보
TICK_AGO = 0 # tick정보는 ago를 to 개념으로 봐야함 ( 0: 오늘 1 : 어제 최대 7일 전 )
TICK_FROM = '08:00:00' # HH:mm:ss (utc 기준임) or None (00:00:00)
TICK_TO = '09:00:00' # HH:mm:ss (utc 기준임) or None (최근)
TICK_AGO 값이 0이면 오늘입니다. 최대 7일 전까지만 검색이 가능하므로, 1주일에 한 번씩은 tick 데이터를 받아야 오랜 기간 데이터를 확보할 수 있습니다.
최근 시간까지 tick 정보를 원하면 TICK_TO 값을 None으로, 0시까지 tick 정보를 원하면 TICK_FROM 값을 None으로 하면 됩니다.
파이썬 소스코드는 아래 github에 있습니다.
github.com/multizone-quant/System_trading_ex/blob/main/get_upbit_ticks.py
'시스템트레이딩' 카테고리의 다른 글
| [시스템트레이딩] 김프를 먹는 자동매매 (5) | 2021.04.30 |
|---|---|
| [시스템트레이딩] API를 이용한 자동매매(4) (13) | 2021.03.28 |
| [시스템트레이딩] 전략 시뮬레이션(8) - 과거 데이터(분봉) 연속으로 가져오기 (18) | 2021.01.12 |
| [시스템트레이딩] API를 이용한 자동매매(3) (0) | 2020.12.12 |
| [시스템트레이딩] API를 이용한 자동매매(2) (10) | 2020.12.12 |
글
[시스템트레이딩] 전략 시뮬레이션(8) - 과거 데이터(분봉) 연속으로 가져오기
이전 분봉 가져오기 글에서 설명한 코드를 정리해서 github에 올립니다.
github.com/multizone-quant/System_trading_ex/blob/main/get_upbit_candles.py
multizone-quant/System_trading_ex
Contribute to multizone-quant/System_trading_ex development by creating an account on GitHub.
github.com
과거 데이터 중 tick과 candle 데이터는 형태가 틀립니다. 따라서 이 데이터를 가져오는 방식도 조금 차이가 있는데요. 기존에는 한 프로그램으로 tick과 candle을 모두 처리하다보니 조금 복잡한 것 같아서 우선 candle만 가져오는 프로그램으로 분리를 했습니다.
동작방식은 아래와 같습니다.
우선 분/일봉 데이터를 최대한 가져옵니다. 여기에 from 보다 과거 candle이 있으면 지운 후 파일에 저장합니다. 그 반대로 아직 받아야할 candle이 더 있으면 to 값을 변경하여 다시 받는 것을 반복합니다.
이렇게 만들어진 파일을 한 파일로 합칩니다.
프로그램 동작시킬 때 필요한 변수 값들입니다.
CANDLE_TYPE = 'min' # 'min' or 'day'
CANDLE_INTERVAL = 1 # 1, 3,5,10,30,60
COIN = 'KRW-HUNT' # 원하는 코인 정보
FROM = '2021-01-11 20:00:00' # 특정 일자부터 받고 싶을 때 : '2021-01-12 10:00:00' (KST임)
TO = None # None:최근시간부터, 특정시간 : '2021-01-12 10:00:00' (KST임)
아직 TO 값을 변경하면서 test하지 않았기 때문에 최근 candle 부터 FROM까지 분/일봉 데이터를 받을 수 있습니다.
TO 값을 입력하여도 정상동작하도록 수정하였습니다. 기존에는 타임존까지 표시하게 하였으나, 그냥 타임존은 생략하도록 (KST기준임) 수정하였습니다. 직관적으로 TO 값을 입력할 수 있도록 TO 값도 KST 기준으로 입력하도록 수정하였습니다. 이때 TO보다 작은 값까지 저장합니다.
만약 하루치를 원하는 경우에는 아래와 같이 입력하시면 됩니다.
----------
버그 수정
2021/1/12 오후 3시 이후로 to 값을 변경하면서 과거 데이터를 모두 가져오는 기능이 동작하지 않습니다. 참고하세요.
연속가져오기에 들어가는 to 시간값은 utc 시간입니다. 따라서 next_to 부분에 들어가는 시간값을 utc 값으로 수정하니 잘 동작합니다.
그리고 일부 데이터가 빠져있는 문제는 아래와 같이 timestamp 값이 None인 구간이 있어서 발생한 문제입니다. 따라서 sort 할때 key값으로 KST 값을 이용하여 문제를 해결하였습니다.

결론적으로 이제 잘 동작합니다.
'시스템트레이딩' 카테고리의 다른 글
| [시스템트레이딩] API를 이용한 자동매매(4) (13) | 2021.03.28 |
|---|---|
| [시스템트레이딩] 전략 시뮬레이션(9) - 과거 데이터(체결, tick데이타) 연속으로 가져오기 (0) | 2021.01.17 |
| [시스템트레이딩] API를 이용한 자동매매(3) (0) | 2020.12.12 |
| [시스템트레이딩] API를 이용한 자동매매(2) (10) | 2020.12.12 |
| [시스템트레이딩] API를 이용한 자동매매(1) (2) | 2020.12.11 |
글
[파이썬] 시간 다루기
거래소에서 전달해주는 과거 데이터의 시간정보의 형태가 거래소마다 틀립니다. 암호화폐 거래소는 주로 UTC를 많이 사용하는데요. 처리의 용이하게 하기 위하여 UTC로 들어오는 시간데이터는 KST로 변환해서 전달해주는 것이 좋습니다.
upbit 거래소에서 과거 tick 데이터를 구하는 url은 아래와 같습니다.
api.upbit.com/v1/trades/ticks?market=KRW-BTC
여기에서 받은 데이터의 json 형태는 아래와 같습니다.

이 함수에서 돌려주는 json 값 중 날짜와 시간은 utc 값입니다. 다른 거래소와의 일관성을 유지하기 위하여 이것을 kst인 +9시간 뒤로 변경하여 처리하는 방법을 정리합니다.
문자열 형태의 일자 시간 정보를 datetime 형태로 변경하는 함수는 strptime()입니다. 입력 데이터의 format에 맞게 인자를 넣으면 됩니다.
dt_tm_utc = datetime.strptime(dt_tm,'%Y-%m-%d %H:%M:%S')
그후 utc와 kst 차이인 9시간을 +한 일자시간을 받기 위해서는 timedeta() 함수를 사용하면 됩니다.
tm_kst = dt_tm_utc + timedelta(hours=9)
이렇게 만들어진 datetime 값을 다시 문자열로 바꾸기 위해서는 strftime()함수를 사용하면 됩니다.
tm_kst_str = tm_kst.strftime('%Y-%m-%d %H:%M:%S')
tm_kst_str에는 날짜와 시간이 공백으로 구분된 문자열이 저장되어 있습니다. 여기에서 split() 함수를 사용하여 날짜와 시간을 분리하면 됩니다.
from datetime import datetime, timedelta
trade_date_utc = "2020-12-26"
trade_time_utc = "17:50:17"
# 일자 + 시간 문자열 만든다.
dt_tm = trade_date_utc + ' ' + trade_time_utc
# datetime 값으로 변환
dt_tm_utc = datetime.strptime(dt_tm,'%Y-%m-%d %H:%M:%S')
# +9 시간
tm_kst = dt_tm_utc + timedelta(hours=9)
# 일자 + 시간 문자열로 변환
tm_kst_str = tm_kst.strftime('%Y-%m-%d %H:%M:%S')
# 공백으로 일자/시간 나누기
tm = tm_kst_str.split(' ')
# kst 기준 날짜/시간을 구한다.
trade_date_kst = tm[0]
trade_time_utc = tm[1]
print(dt_tm_utc)
print(trade_date_kst, trade_time_utc)
print('')
그 결과는요..
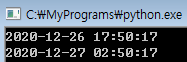
변환이 잘 되었군요.
'파이썬' 카테고리의 다른 글
| [파이썬] 실행 시 환경 변수 읽기 쓰기 (0) | 2022.01.17 |
|---|---|
| [파이썬] 파이썬을 이용하여 날짜/시간 다루기 (0) | 2022.01.14 |
| [파이썬] glob, os 정리, 폴더(dir) 그리고 파일 다루기 (1) | 2020.12.23 |
| [파이썬] 텔레그램봇 이용한 시세 봇(1) (2) | 2020.07.17 |
| [파이썬] Selenium Webdriver, 셀레니움 웹드라이버를 이용하여 웹페이지 동작시키기 (0) | 2020.07.08 |
글
[파이썬] glob, os 정리, 폴더(dir) 그리고 파일 다루기
directory 만들고 지우기, 파일 이름 검색하기 등등 dir과 파일에 관련된 코딩이 필요할 때 glob와 os에 대하여 정리합니다.
우선 아래 두 패키지를 import 합니다.
import os
import glob0. 현재 폴더 위치 얻기
cwd = os.getcwd()
윈도우와 리눅스를 구분하는 방법으로 \\가 있는지 확인하면 됩니다.
if "\\" in cwd :
print('win')
1. 폴더(directory) 만들기
원하는 이름의 dir를 만듭니다. 전략 실행하는 중에 매매와 상태에 대한 정보를 저장하여야합니다. 간단하게 파일을 사용할 수도 있고 DB를 사용할 수 있습니다. 우선 간단하게 파일을 사용합니다. 전략별로 혹은 일자별로 별도의 홀더를 만들어서 관리하면 좋을 것 같습니다. 따라서 필요한 이름으로 폴더를 만들 필요가 있습니다.
폴더를 만드는 방법은 간단합니다.
os.mkdir('.\\test')2. 폴더(directory) 지우기
일자가 지나면 기존 전략으로 생성한 폴더를 지워야하는 경우가 있습니다. 이를때는 rmdir를 사용합니다 단 rmdir()을 사용하기 전에 해당 폴더는 비워져있어야 합니다.
rmdir('.\\test')
3. 파일명 검색하기
특정 폴더에 있는 파일명을 검색해봅시다. 프로그램이 비정상적으로 종료가 된 후 다시 시작할 때 기존 매매 상태로 복귀를 하여야 합니다. 이때 전략 실행 중 상태 값을 저장한 파일을 읽어서 이전과 같은 상태로 만들어야 합니다.
예를들어 .\\working 폴더에 아래와 같은 상태 정보가 저장되어 있다고 가정해봅시다.

우리가 해야할 일은 여기에 있는 파일 명을 list로 받아서 각 파일을 읽은 후 해당 ticker의 상태 값을 읽어야 합니다. 이때 사용할 함수는 glob.glob입니다. filter에 들어갈 적절한 문자열을 결정해서 전달하면 됩니다.
def get_filenames() :
files = []
filter = '.\\working1\\' + '*_order_status.txt'
for filename in glob.glob(filter):
files.append(filename)
for fname in files :
print (fname)
return files
이 코드를 실행하면 아래과 같이 working에 있는 파일명 list를 받을 수 있습니다. 파일명에 있는 ticker 정보를 바탕으로 해당 ticker의 상태 정보를 update하면 됩니다.

4. 파일 지우기
트레이딩이 끝나면 중간에 발생한 파일을 지워야 하는 경우가 있습니다. 특히 일 단위로 정산을 하는 경우에는 동작 중 발생한 파일을 반드시 지워야합니다.
3번에서 설명한 파일명 검색 후에 원하는 파일을 지우는 예제입니다. 아래 예제에서는 'BCH'를 가진 파일을 지웁니다.
filter = '.\\working1\\' + '*_order_status.txt'
for filename in glob.glob(filter):
if filename.find('BCH') >= 0 :
os.remove(filename)
이 코드를 실행한 결과입니다. 'BCH'를 가진 파일만 지웠습니다.

'파이썬' 카테고리의 다른 글
| [파이썬] 파이썬을 이용하여 날짜/시간 다루기 (0) | 2022.01.14 |
|---|---|
| [파이썬] 시간 다루기 (1) | 2020.12.27 |
| [파이썬] 텔레그램봇 이용한 시세 봇(1) (2) | 2020.07.17 |
| [파이썬] Selenium Webdriver, 셀레니움 웹드라이버를 이용하여 웹페이지 동작시키기 (0) | 2020.07.08 |
| [파이썬] 일정시간 입력이 없으면 자동으로 돌아오는 입력, input (0) | 2020.05.31 |